Auction Arena
👋 Hi, there! This is the project page for our paper: “Put Your Money Where Your Mouth Is: Evaluating Strategic Planning and Execution of LLM Agents in an Auction Arena”.

AucArena Code
Code for running demo and experiments in the paper.

AucArena Demo
Interactive demo to play with, for humans and AI.

AucArena Paper
Everything you need to know about our work.
Abstract
Can Large Language Models (LLMs) simulate human behavior in complex environments? LLMs have recently been shown to exhibit advanced reasoning skills but much of NLP evaluation still relies on static benchmarks. Answering this requires evaluation environments that probe strategic reasoning in competitive, dynamic scenarios that involve long-term planning. We introduce AucArena, a novel simulation environment for evaluating LLMs within auctions, a setting chosen for being highly unpredictable and involving many skills related to resource and risk management, while also being easy to evaluate. We conduct several controlled simulations using state-of-the-art LLMs as bidding agents. We find that through simple prompting, LLMs do indeed demonstrate many of the skills needed for effectively engaging in auctions (e.g., managing budget, adhering to long-term goals and priorities), skills that we find can be sharpened by explicitly encouraging models to be adaptive and observe strategies in past auctions. These results are significant as they show the potential of using LLM agents to model intricate social dynamics, especially in competitive settings. However, we also observe considerable variability in the capabilities of individual LLMs. Notably, even our most advanced models (GPT-4) are occasionally surpassed by heuristic baselines and human agents, highlighting the potential for further improvements in the design of LLM agents and the important role that our simulation environment can play in further testing and refining agent architectures.
About Auction Arena
Welcome to the battleground where AI, especially Large Language Models (LLMs), test their mettle in an environment pulsating with strategy, risk, and competition - the Auction Arena!
Introduction: A Dive into Dynamic Auctions with LLMs
Exploring AI’s capabilities often pivots around static benchmarks. But what happens when we plunge LLMs like GPT-4 and Claude-2 into a dynamic, competitive, and strategically demanding environment? Our research, presented in our new paper titled “Put Your Money Where Your Mouth Is: Evaluating Strategic Planning and Execution of LLM Agents in an Auction Arena”, explores just that!
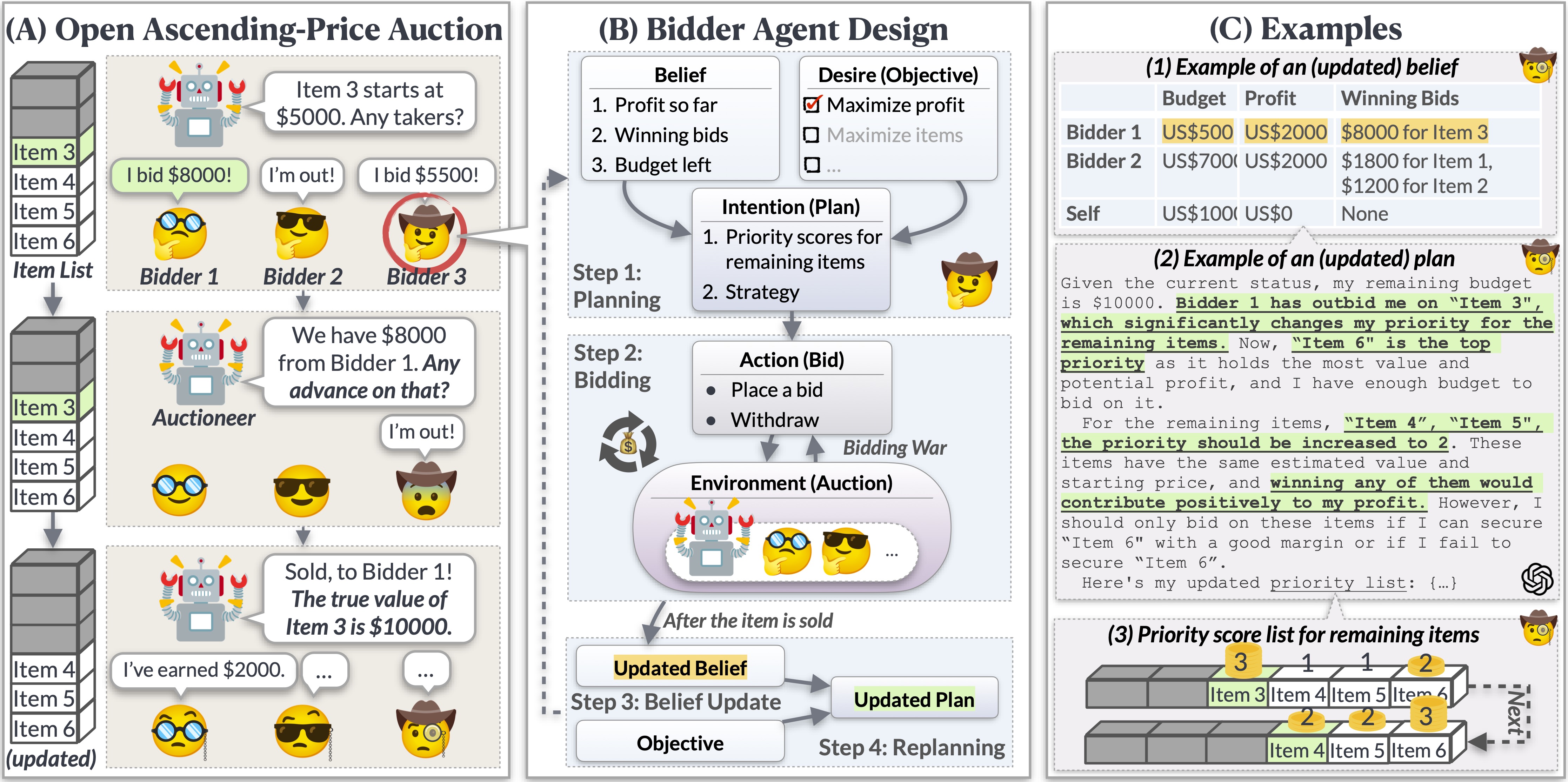
Crafting AI Bidders: Planning, Bidding, and Replanning
Inspired by the Belief-Desire-Intention (BDI) model, our Bidder Agent navigates through the auction with a robust mechanism involving Planning-Bidding-Belief Update-Replanning, ensuring it can strategize, bid, reassess, and replan to navigate the tumultuous waters of the auction.
Analyzing LLM Agent: Planning, Execution, and Adaptability
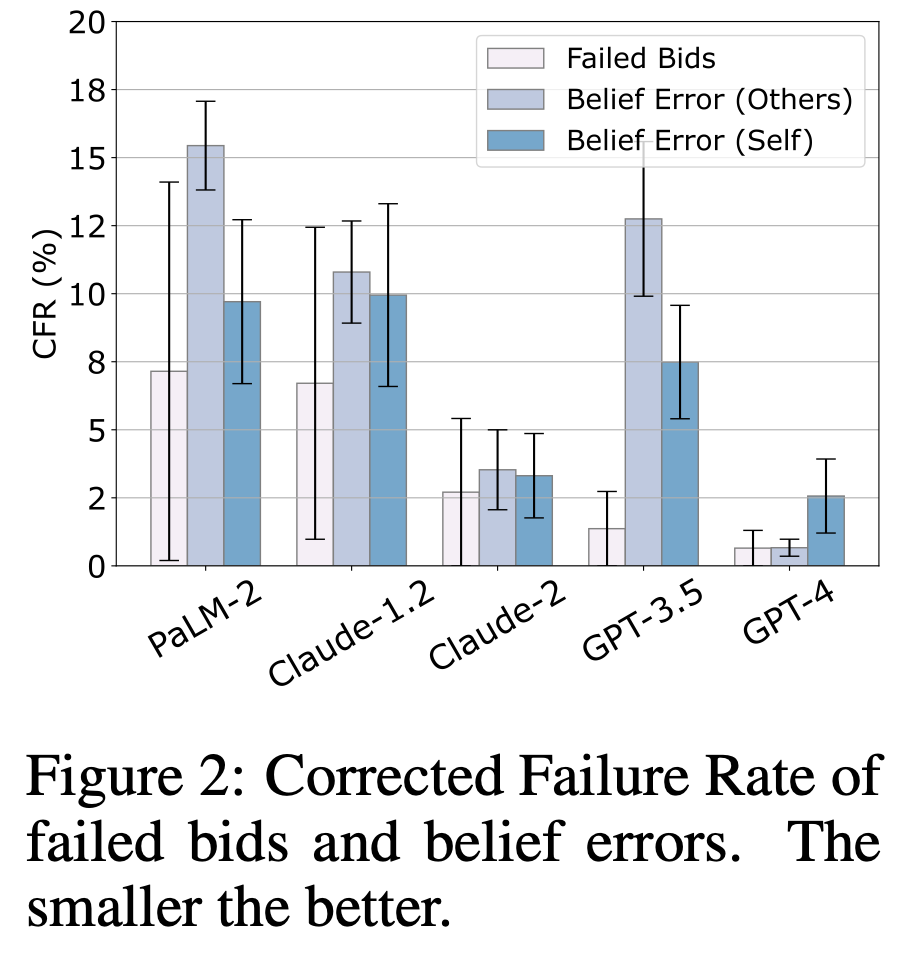
The core abilities of LLMs were put under the microscope. First of all, their basic skills: better LLMs, fewer belief errors:
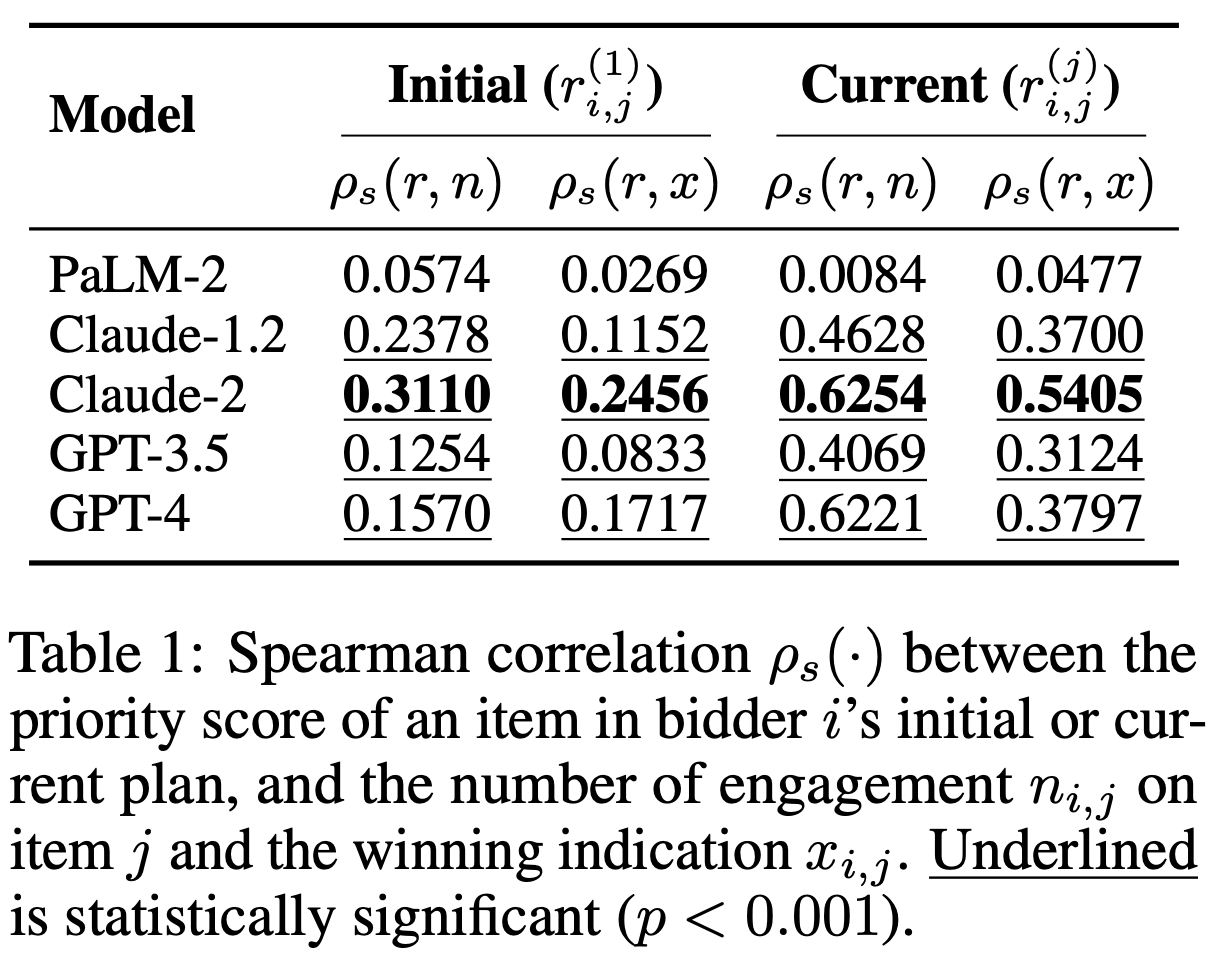
When examining the faithfulness between strategic planning and execution, Claude-2 emerged as a decisive “doer”:
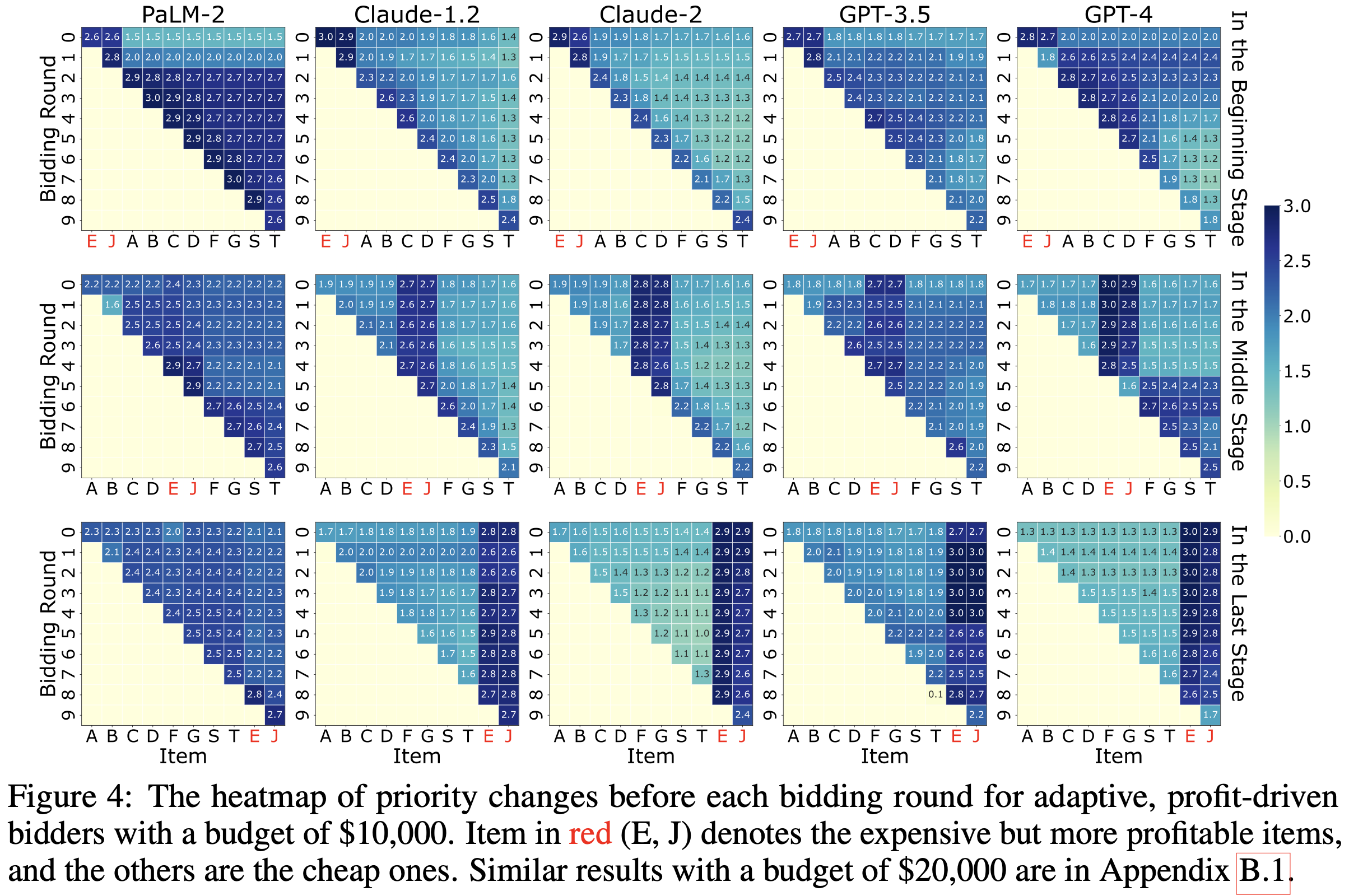
Being adaptive to the changing environment was crowned as a lucrative trait in the auction environment:
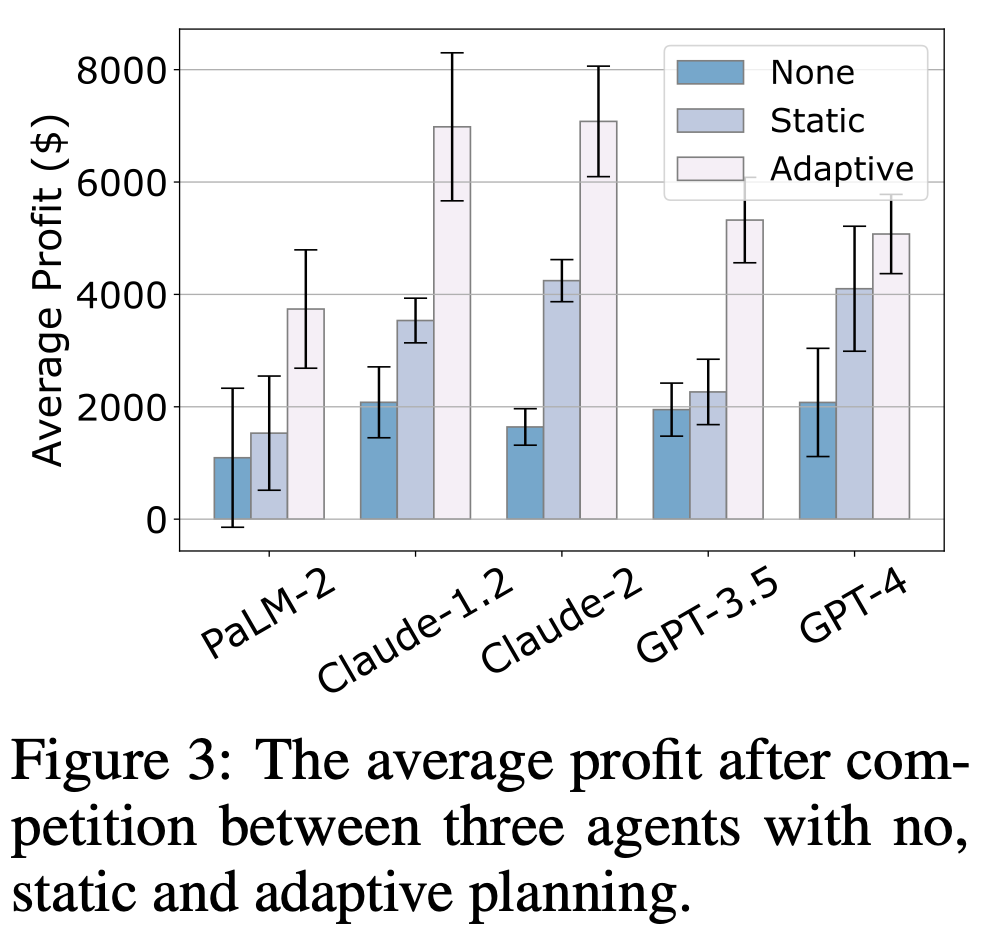
And thus, you will see a clear planning change under different item orders, showing the fact that, by being adaptive, certain LLM agents can save money for the future!
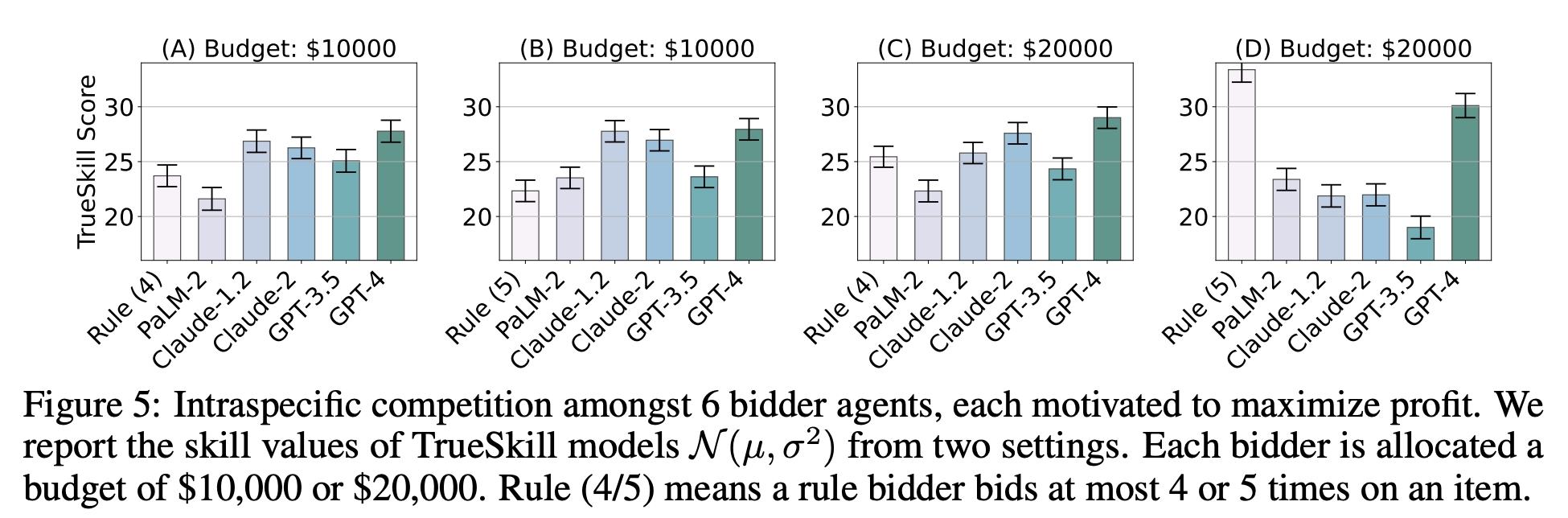
The Battle of the LLMs in the Auction Arena
Pitting various LLMs against each other, we witnessed a rollercoaster of strategies and performances. GPT-4 showed promise, and Claude-2 was impressive, yet our heuristic rule-bidder occasionally stole the show, especially when the budgetary stakes were high.
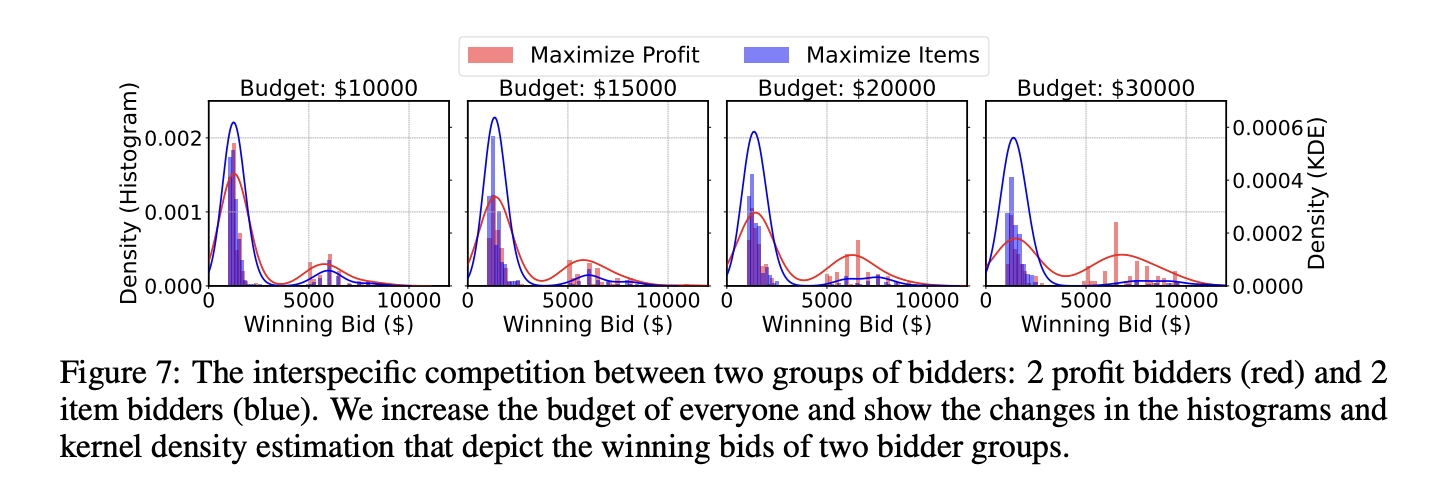
Emergent Niche Specification among Varied Bidders
When introducing bidders with disparate goals - Profit Bidders and Item Bidders - the auction morphed into an ecosystem of “niche separation,” where agents carved out their strategic domains, chasing after different valued items, much akin to ecosystems in nature.
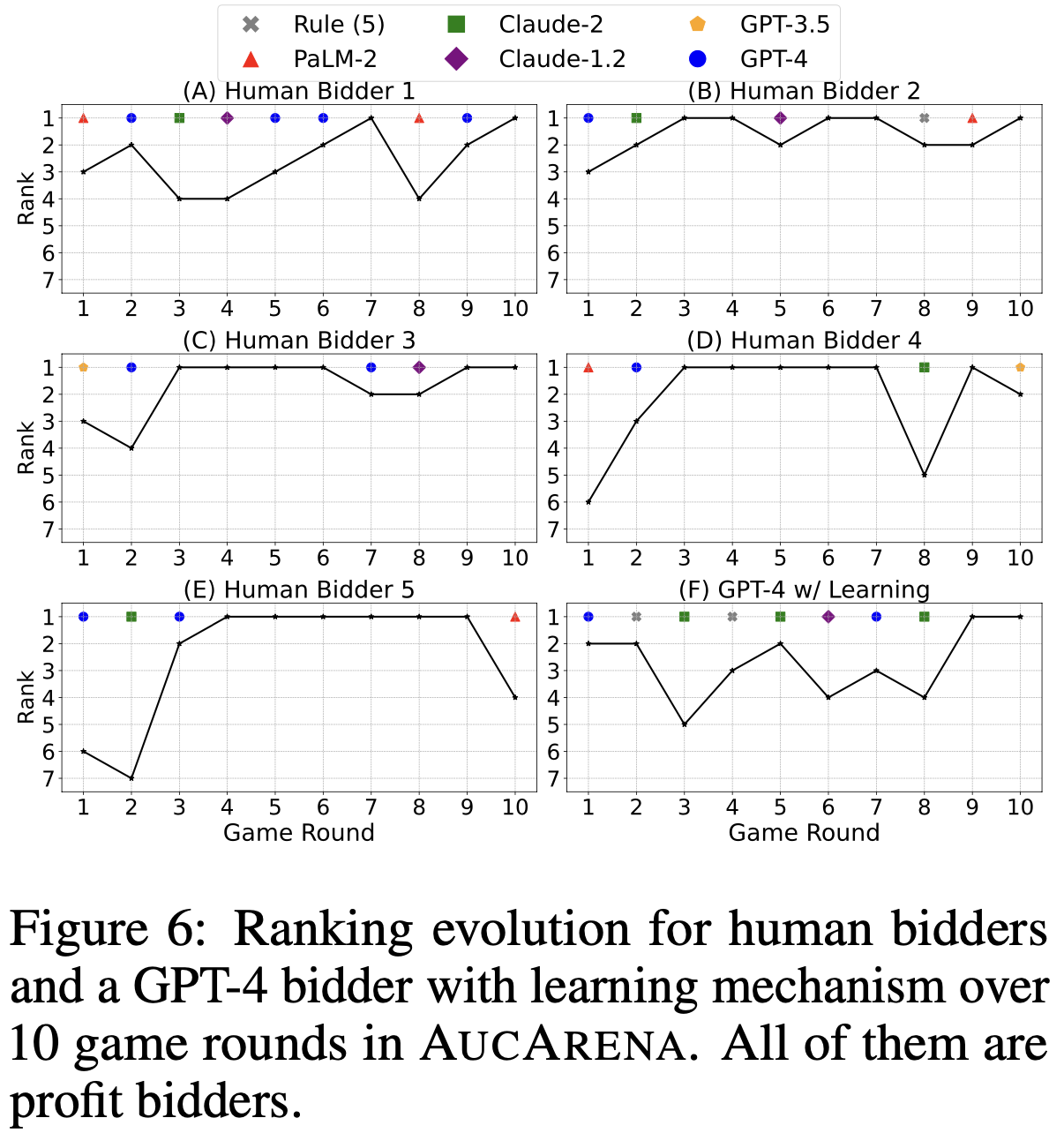
Testing Your Auction Skills Against AI
Dare to step into the arena yourself? Engage with our live auction arena and pit your strategic auctioning skills against AI. Can you outbid the machines?
Wrapping Up the Bidding War: Insights and Implications
Our exploration of the Auction Arena reveals the multifaceted capabilities and potential areas of improvement for LLMs in strategic, dynamic, and competitive scenarios. From showcasing adept resource management to occasionally being outshone by heuristic baselines and humans, the LLMs demonstrated both their strengths and weaknesses in our auction environment.
For a comprehensive dive into our methodologies, findings, and insights, explore our research paper. There are many tasks left for future research, such as manipulating the simulation for more details and setups, enabling lifelong learning for LLM agents, and making LLM agents more aware of their desires, etc.
Authors
Jiangjie Chen
https://jiangjiechen.github.io
Siyu Yuan
https://siyuyuan.github.io
Rong Ye
https://reneeye.github.io
Bodhisattwa Prasad Majumder
https://www.majumderb.com
Kyle Richardson
https://www.nlp-kyle.com
Acknowledgements
This work is supported by the following organizations:
Allen Institute for AI
Fudan University
Citation
If you find this work useful to your research, please kindly cite our paper:
@article{chen2023money,
title={Put Your Money Where Your Mouth Is: Evaluating Strategic Planning and Execution of LLM Agents in an Auction Arena},
author={Jiangjie Chen and Siyu Yuan and Rong Ye and Bodhisattwa Prasad Majumder and Kyle Richardson},
year={2023},
eprint={2310.05746},
archivePrefix={arXiv},
primaryClass={cs.CL}
}